Playphrase is rather stunning, and be prepared to lose a good chunk of time exploring it. You have been warned.
PlayPhrase will assemble a clip of movie scenes all having the same phrase, a small supercut if you will. I could try it, but maybe just see yourself and see what happens if we make some art
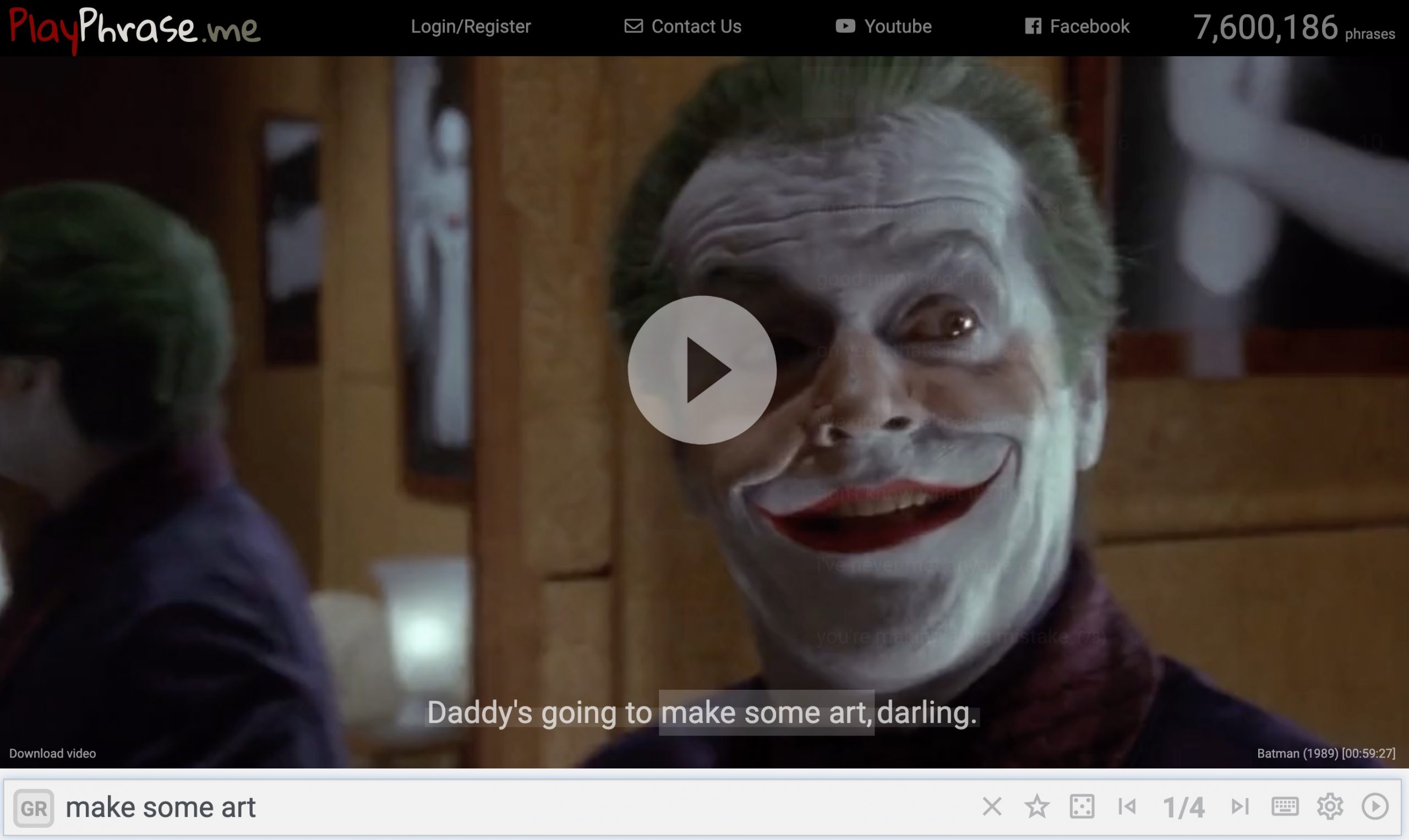
So now it is on you, use Play Phrase to generate something that describes to the vast world ignorant of DS106 or MYFest25 … what it is really about.
Go to the next level and turn it into a dialogue:
MYFest25 is about recharge and renewal exploring
- open educational practices, Artificial Intelligence and digital literacies
- critical pedagogy and socially just education
- wellbeing and joy
- community building and community reflection
or for DS106
“I’ve never seen anything like it“
Reply in Mastodon for this Daily Create to @[email protected] and include the tag #tdc4920
Find and reply to today's Daily Create as newest post in Mastodon: